
目次
1. はじめに
大規模言語モデル(LLM)は、単なる「賢いチャットボット」ではありません。その背後には、自然言語を確率的なシーケンスとして捉え、膨大なパラメータ空間の中で言語の構造を再現する、洗練された技術体系が存在します。
本記事では、LLMが「何ができるか」という応用事例の紹介ではなく、LLMが「なぜ、どのようにして」その驚異的な能力を発揮するのか、その技術的根幹を深く掘り下げて解説します。
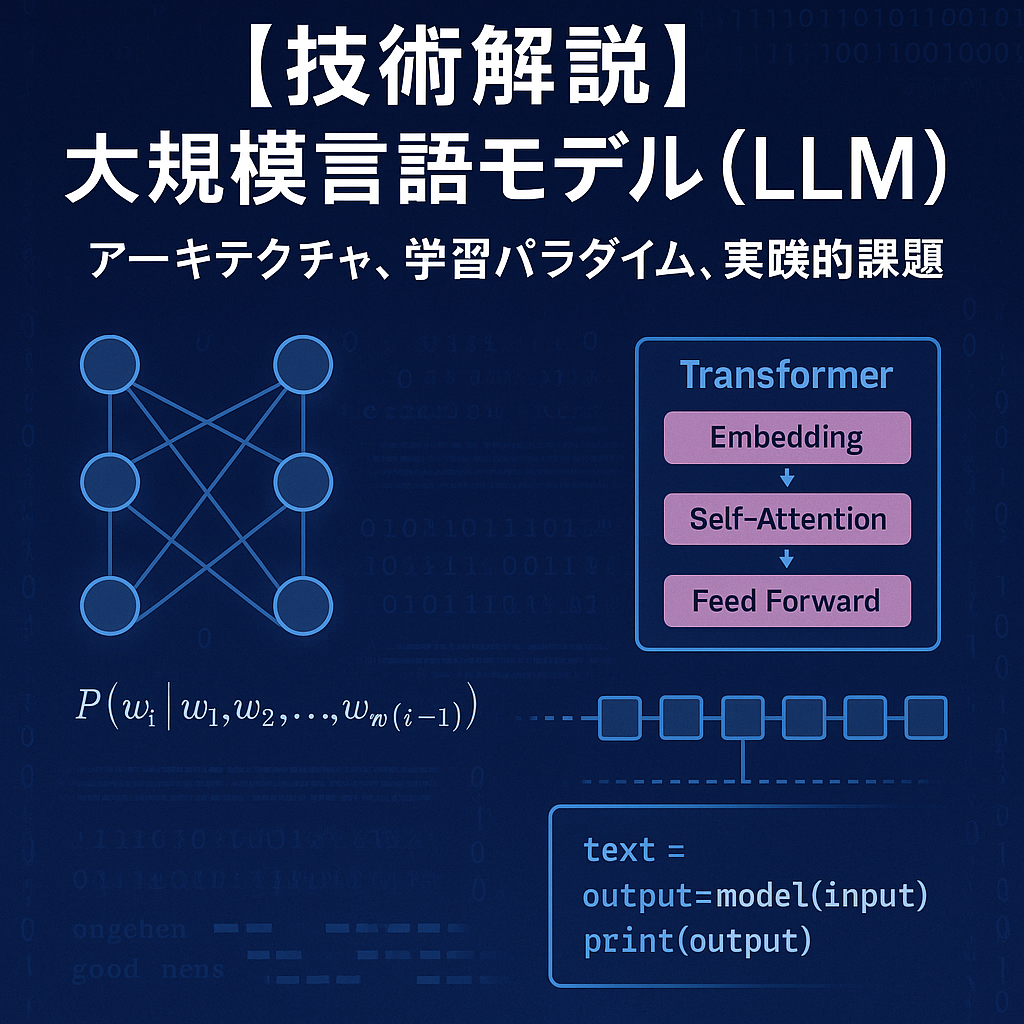
2. LLMの技術的本質:自己回帰的な確率モデル
LLMの根幹は、自己回帰モデル(Autoregressive Model)にあります。これは、ある単語列(トークンシーケンス)が与えられた際に、次に来る単語を確率的に予測するタスクを繰り返し行うモデルです。
$$P(w_i | w_1, w_2, …, w_{i-1})$$
すなわち、LLMが行っているのは、それまでの文脈に基づき、語彙の中から次に出現する確率が最も高い単語を選択し続けるという、極めてシンプルな処理の連続です。この確率分布を、数十億から数兆にも及ぶパラメータを用いて極めて高次元の空間で学習・表現することで、人間が生成したかのような自然で文脈に沿ったテキストを生成できます。
3. LLMアーキテクチャの核心:「Transformer」詳解
現代のLLMのほぼ全てが、2017年に発表された「Transformer」モデルを基盤としています。Transformerが画期的であったのは、それまでの主流であったRNN(再帰型ニューラルネットワーク)が抱えていた長期依存性の問題を、自己注意機構(Self-Attention Mechanism)によって克服した点にあります。
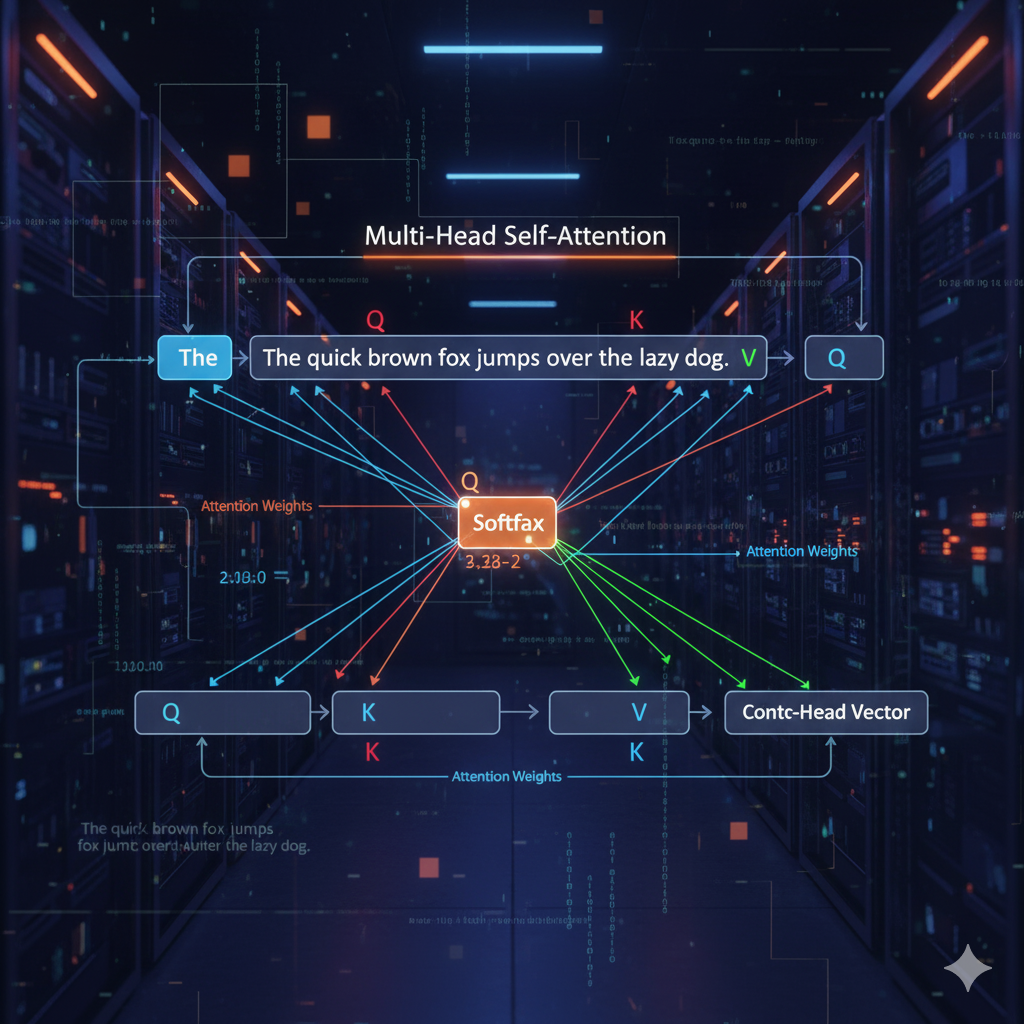
3.1. 自己注意機構(Self-Attention)
Self-Attentionは、文章中のある単語を処理する際に、文章中の他の全ての単語との関連性の強さを動的に計算し、その関連度に応じて文脈情報を加味する仕組みです。これにより、単語間の距離に関わらず、文法構造や意味的な関連性を直接的に捉えることができます。
この関連度は、各単語から生成される3つのベクトル「クエリ(Query: Q)」「キー(Key: K)」「バリュー(Value: V)」を用いて計算されます。
- 関連度の計算: 注目している単語のQベクトルと、他の全単語のKベクトルとの内積を計算し、関連性のスコアを算出します。
- 重み付け(Softmax): このスコアを正規化(Softmax関数を適用)し、合計が1になるような「注意の重み(Attention Weight)」に変換します。
- 文脈ベクトルの生成: 各単語のVベクトルを、対応する「注意の重み」で加重平均し、文脈情報を凝縮したベクトルを生成します。
この計算を複数のヘッドで並列に行う「マルチヘッドアテンション」により、モデルは多様な観点から単語間の関係性(例:文法的な関係、意味的な関係など)を同時に学習できます。
3.2. Positional Encoding(位置エンコーディング)
Transformerは、構造上、単語の順序情報を保持できません。そこで、各単語の埋め込みベクトルに、その単語がシーケンスのどの位置にあるかを示す「Positional Encoding」というベクトルを加算します。これにより、モデルは単語の相対的・絶対的な位置関係を把握することが可能になります。
4. LLMを高度化させる学習パラダイム
LLMの驚異的な性能は、巨大なモデルアーキテクチャだけでなく、それを訓練するための高度な学習手法によって支えられています。
4.1. 事前学習(Pre-training):自己教師あり学習
LLMは、まずインターネット上の膨大なテキストコーパスを用いた自己教師あり学習によって、言語に関する汎用的な知識を獲得します。この事前学習には、主に2つのアプローチがあります。
- Causal Language Modeling (CLM): GPTシリーズなどで採用されている自己回帰的なアプローチ。文章を左から右へと読み込み、次に来る単語を予測するタスクを解き続けます。文章生成タスクに非常に強い特性を持ちます。
- Masked Language Modeling (MLM): BERTなどで採用されているアプローチ。文章中の一部の単語をマスク([MASK]トークンに置換)し、そのマスクされた単語を周囲の文脈から予測します。文章全体の双方向の文脈を理解する能力に長けており、分類や抽出タスクで高い性能を発揮します。
4.2. 人間の意図への整合:Instruction TuningとRLHF
事前学習済みのモデルは汎用的ですが、必ずしもユーザーの指示(Instruction)に忠実に応答するわけではありません。そこで、人間の意図に沿った応答を生成させるための追加学習が行われます。
- Instruction Tuning (指示チューニング): 「質問:〇〇、回答:△△」といった形式の高品質なデータセットを用いてモデルをファインチューニングする手法。これにより、モデルは対話形式で指示に従う能力を獲得します。
- RLHF (Reinforcement Learning from Human Feedback): 人間のフィードバックを基に強化学習を行う手法で、近年のLLMの性能向上に大きく貢献しました。
- Reward Modelの学習: 同じプロンプトに対してLLMが生成した複数の回答を人間がランク付けし、そのランキングデータを教師データとして「報酬モデル」を学習させます。このモデルは、より好ましい回答に高い報酬(スコア)を与えるように訓練されます。
- 強化学習によるファインチューニング: LLM(Policy Model)が生成した回答を報酬モデルで評価し、その報酬が最大化されるようにLLMのパラメータを強化学習(PPOアルゴリズムなど)で更新します。これにより、モデルはより人間にとって自然で、安全で、有用な回答を生成するように洗練されていきます。
4.3. 効率的な適応技術:PEFT(Parameter-Efficient Fine-Tuning)
数千億パラメータを持つLLM全体をファインチューニングするのは、計算コストが非常に高くなります。そこで、PEFTという、モデルの大部分のパラメータを凍結し、ごく一部のパラメータのみを更新する効率的な手法が開発されました。代表的な手法にLoRA (Low-Rank Adaptation)があり、これはTransformer層に小さな追加の重み行列を導入し、その部分だけを学習することで、少ない計算資源で効率的にモデルを特定のタスクに適応させることができます。
5. 実践における高度な課題と技術的アプローチ

LLMを実運用に載せるには、その原理的限界から生じる課題への技術的対策が不可欠です。
課題1: ハルシネーション(事実に基づかない情報の生成)
原理: LLMはあくまで確率的に最もそれらしい単語列を生成するモデルであり、真実性を保証する機構を持たないため、学習データに存在しない、あるいは誤った情報を事実であるかのように生成します。
技術的対策:
- RAG (Retrieval-Augmented Generation): ユーザーの入力に関連する情報を、外部の信頼できるナレッジベース(例: 社内文書、製品マニュアル)から検索(Retrieve)し、その内容をプロンプトに埋め込んでLLMに渡すことで、事実に基づいた(Grounded)回答を生成させるアーキテクチャ。Vector Databaseを用いた高速なセマンティック検索が鍵となります。
- Groundednessの評価: 生成された回答の各文が、参照したどの情報源に基づいているかを検証し、根拠のない記述を検出・フィルタリングする仕組みを導入します。
課題2: プロセスの不透明性(ブラックボックス問題)
原理: 膨大なパラメータを持つニューラルネットワークの内部状態を人間が完全に解釈することは極めて困難です。
技術的対策:
- Chain-of-Thought (CoT) / Tree of Thoughts (ToT): LLM自身に回答に至るまでの思考プロセスを段階的に記述させるプロンプト技術。これにより、回答の論理的妥当性を検証しやすくなります。ToTはさらに、複数の思考経路を木構造で探索・評価し、より精度の高い結論を導きます。
- 解釈可能性(Interpretability)技術: 特定の出力に対して、モデル内部のどのニューロンやアテンションが強く寄与したかを可視化・分析する研究が進められています。
課題3: LLMの評価と継続的運用(LLMOps)
原理: LLMの性能は多面的であり、単一の指標で評価することは困難です。また、一度導入すれば終わりではなく、継続的な性能監視と改善が必要です。
技術的対策:
- ベンチマーク評価: MMLU(一般知識)、HumanEval(コード生成)、日本語特化のベンチマーク(例: Elyza-tasks-100)など、複数の標準化されたベンチマークを用いて、モデルの多角的な能力を定量的に評価します。
- LLMOps (LLM Operations): プロンプトのバージョン管理、出力品質の監視、ユーザーフィードバックの収集、定期的なモデルの再評価・ファインチューニングといった、LLMアプリケーションを安定して運用・改善するための技術スタックと運用プロセスの確立が重要となります。
6. まとめ
本記事では、LLMを支える技術的要素を深掘りしました。LLMは、Transformerアーキテクチャを基盤とし、自己教師あり学習で得た汎用的な能力を、RLHFなどの高度な手法で人間の意図に整合させることで実現されています。
ビジネスや研究開発でLLMを真に活用するためには、こうした技術的な仕組みと、そこから生じる本質的な課題を深く理解し、RAGやLLMOpsといった適切な技術的アプローチを講じていくことが不可欠です。LLMは今も急速に進化しており、その動向を継続的に追っていくことが、今後の技術革新の鍵となるでしょう。
